| Updating Python Codes 0.1 and 2.1 (p.176) for Figs. 2.1 and 2.2 (p.8) | |
|
<元のコード code 2.1.py> 30個の実験データ xi (i=1..N)を小さい順に並べ、xiを横軸に、i を縦軸に取ってグラフ化します。 原著では乱数を使う次のコードで処理しています。
|
<code2.1bb.py からのグラフィックス出力>
|
|
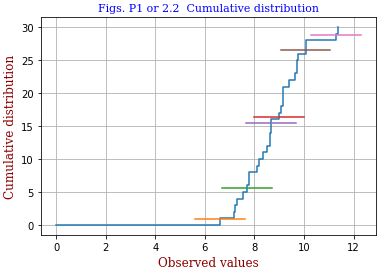
<モジュール化> 上右の図は隣接する(xi,yi) を __| のパターンでつないだものですが、グラフとしては 隣接する節点(uk,vk)間に直線を引いたものとなります。max k は max i の倍です。 この作業は一つのモジュールとしてまとめておくとプログラミングが楽になります(Modula-2 では当然の発想です)。 というわけで次のようなモジュールを試作しました。
|
<code2.1cc.py からのグラフィックス出力>
|
|
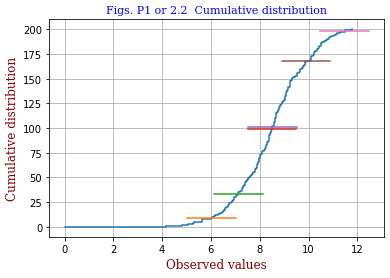
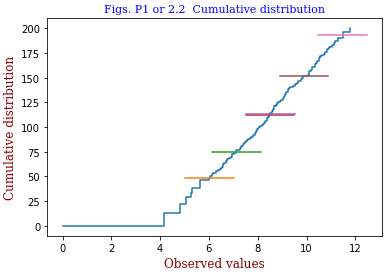
<code 2.1cc.py> code 2.1cc.pyでは、 正規乱数 xi(i=1,200) を200個発生させて小さい順に並べ、xiを横軸に、i を縦軸に取ってグラフとしています。 データ毎の幅を一定として描いたグラフが真ん中の図です。 データ数が多くなるに従って誤差関数 erf(x) に近づくことが想像できます。 <縦軸の目盛り間隔に傾斜をつける> 目盛りの取り方を工夫すれば上の曲線的グラフを直線的なものに変えることができます。ここでは各データ幅を wi ∝ 1/gauss(xi-av,σ) としています。gauss関数の 0.5/σ2とあるのを0.3/σ2として描いたのが右図です。 ±σ 等の位置を表す横線が中心に向かって移動していますが、中心付近でデータ密度が高いことを反映しています。 |
<code2.1cc.py からのグラフィックス出力>
|