|
<累積分布の縦軸>
最も単純な累積分布図は、Part (2) の図(ii)のタイプです。縦軸は小さい順に1個目、2個目、・・・、n個目で、横軸は身長やバナナの小売り価格など「ものの値」です。 データ数がnであれば、縦軸の範囲は 0〜n とするのが普通でしょう(例えばDr.Berendsen の図2.1)。 縦軸を確率(パーセント表示)にするには、そのグラフの上端を100%、下端を0%に書き換えればよいと誰でも思うでしょう。 ところがDr.Berendsen の図2.2では 1%〜99% となっている。 これには何か訳があるに違いないというのがこのページの話題です。 余談になりますが、入試判定では成績を上から順に並べて累積分布図を作っています。 100人程度までの受験生であればExcelが使えます。予定枠近傍で変化率の大きいところが合格ラインの第一案になります。 |
<0%と100%では発散するのか?>
累積分布図の縦軸範囲が1%〜99%なのは、0%と1%は計算できないから仕方ないのではないかと思いあたりました。例えば次のf(y)があります。 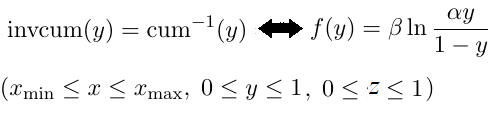
x は値を表す変数、yとzは確率を表す変数です。 左辺の invcum(y) は累積分布関数 cum(x)の逆関数です。f(y) が invcum(y) のよい近似になっていれば Part (2) の図 が簡単に得られることになっておおいに便利になります。 |
|
<一点で合わせる>
y=1/2 で関数と一次導関数が一致するという条件を課するとα=2980, β=0.624が導かれます(σ=1、xmin=2, xmax=8)。 図で実線が y=invcum(x), 破線が y=f(x) です。意外といけそうですが発散する直前で精度が落ちています。 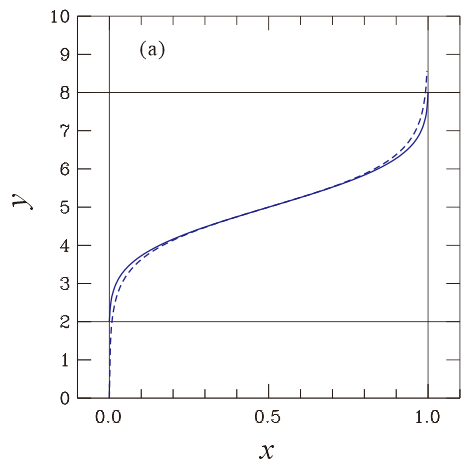
|
<所詮近似は近似>
σが大きくなると近似が悪くなります。f(x)の形を維持したままで精度を保持しようとすれば、パラメータ(自由度)を増やす必要があります。 しかしパラメータの最適値は分布のようすに依存しますので実用的な近似関数を作るのはかなり面倒になります。 invcum(x) のコーディングするほうが楽かもしれません。 <まとめ> Dr.Berendsen の変換が y→ 0, 1 で対数的に発散する可能性を指摘しました。実は近似式の問題ではなく、或るモデルを正しく解けば必然的に発散することに気づきました。 それを次で話します。 |