|
<Dr.Berendsenのアプローチ>
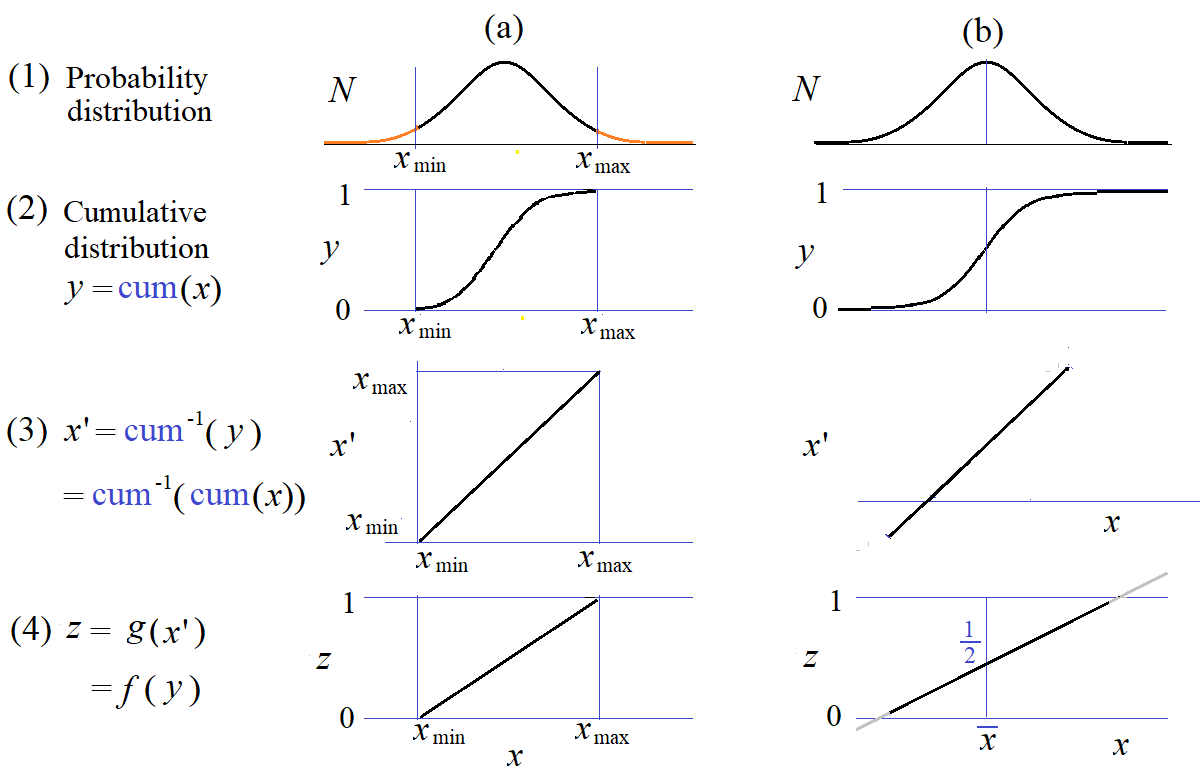
このシリーズの主題は、正規分布に従う連続量の累積分布 y=cum(x) を z=f(y) で変換して線形の x-z 関係にする、
そしてその f を離散量の累積分布に適用して直線範囲が広がることを確かめるということです。
さて、Dr. Berendsen の方法は(b)モデルに相当するのではないかと思われます。
関数f(y) つまり y-z関係は次の形になります。
Bは任意定数Bです。
通常の累積分布は x=xmin で y=0, x=xmaxでy=1 となります。
f関数は y=0,1 で発散するので一歩手前の有限区間 y=[ε, 1-ε]で考えることにします。zはそれぞれ z=ε, 1-ε
となるようにしましょう。そうすればBが決まります。
なおDr.Berendsen は ε=0.01 (1%) としているようですので、ここでもそうします。
|
<連続量に対する(b)モデル型累積分布>
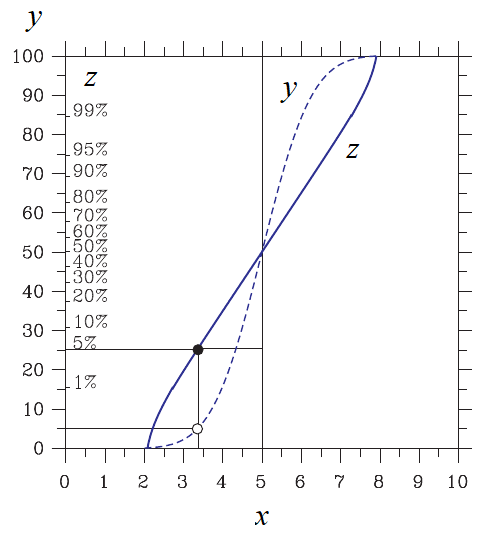
例としてa=5を中心とし、x=2...8 を定義域とする正規分布を扱います。通常の累積分布が図の x-y でx=2でy=0, x=8でy=1 (100%) です。
x-z は変換を施して得られた累積分布です。○はyの5%、●はzの5%です。
εを(例えば 0.001に)小さくすればx-z は上下にどんどん延びて実用性がなくなりますからε=0.01は妥当な選択であるといえるでしょう。
Part (1) の図では yもzも 0%〜100% でしたが、ここではyのみ 0〜100%でzは 1%〜99%です (例えば 0.5% の位置は? と問われても図では分かりません)。
|
|
<離散分布対する(b)モデル型累積分布>
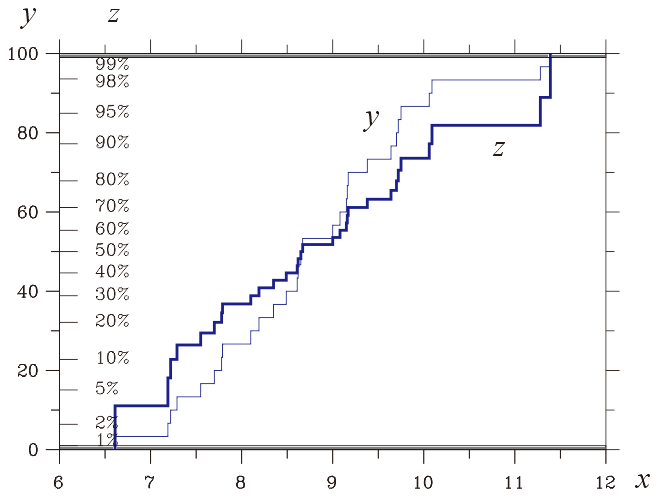
Dr.Berendsen の「データ・誤差解析の基礎」の図2.2に用いられた離散データを題材とします。
細線は通常の累積分布 x-y で、範囲は0〜100(%)です。
太線は変換fによって得られた x-z関係です(1-99%)。陰影の領域は z<ε, z>1-ε なので除外すべきです。
図2.2 と矛盾しないように思えます。
|
<1%〜99%再訪>
(b)モデルでは上図(b-3)で特異点が現れます。この特異性はerf-1と類縁関係にあるerfc-1の特異性
erfc-1(x)〜√log |x| で説明できます。
Part (4) では、(a)モデルを簡便に扱うために
invcum(x)の近似式を考えました。そしてこの関数が端点で大きな勾配をもてば log x/(1-x) が有用であると分かりました。
しかし、この近似式は本質的に特異性をもつ(b)モデルのほうに向いていると思われます。
<まとめ>
Dr.Berendsen の累積分布図が 0%と100% を排除している理由を推測しました。
1%〜99% でなく 0.1%〜99.9%でもよいのですが、正規分布の裾野が強調されるだけなので実効性はないでしょう。いずれにせよ(a)モデルのほうが理にかなっています。
|